🏷️ Фиксированная цена
⏱️ Расчёт за 24 часа
Ежедневно без выходных с 08:00 до 21:00 по Мск
Работаю по всей России, Беларуси, Казахстану

GET-параметры в URL
Как найти и обезвредить дубли страниц, убивающие ваше SEO
Читайте также: в нашей предыдущей статье мы подробно разбирали директиву clean-param в файле robots.txt — мощный инструмент для указания поисковым системам, какие параметры нужно игнорировать при сканировании.
GET-параметры в URL: как найти и обезвредить дубли страниц, убивающие ваше SEO?
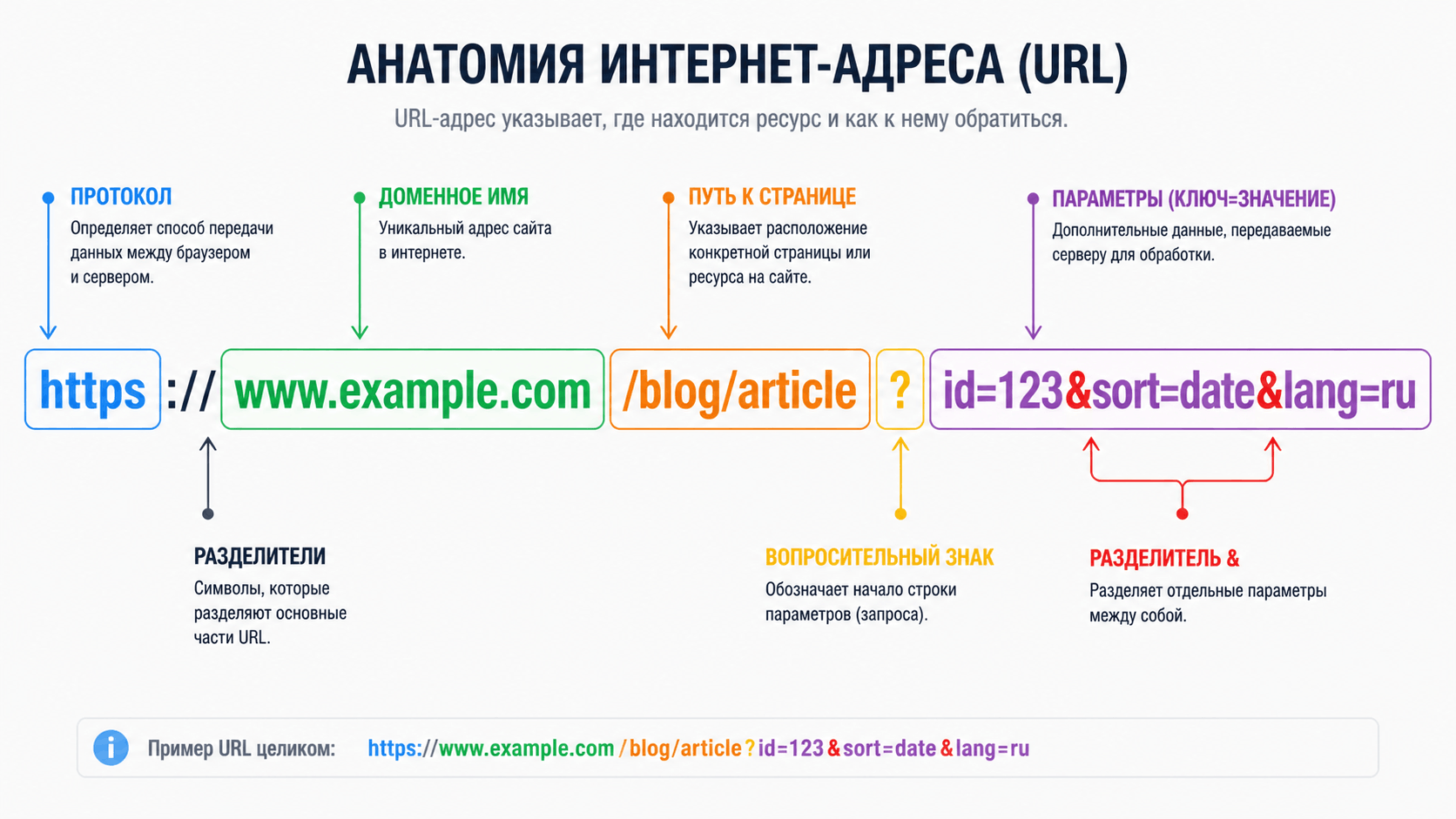
GET-параметры — это пары "ключ-значение", добавляемые в URL после знака вопроса `?` и разделенные амперсандом `&`. Они передают серверу дополнительные данные для обработки запроса. Проблема для SEO возникает, когда один и тот же контент становится доступен по разным URL из-за этих параметров, создавая дублирующийся контент. Поисковые системы (ПС) вынуждены выбирать, какая версия URL является канонической, что рассеивает вес ссылок и ухудшает ранжирование.
Оглавление
1. Что такое GET-параметры и зачем они нужны?
GET-параметры — это часть URL-адреса, следующая после символа `?`. Они используются для передачи данных на сервер методом HTTP GET. Их структура проста:
https://example.com/catalog/products?category=shoes&size=42&color=black
- `?` — разделитель, начало строки параметров
- `category=shoes` — первый параметр, где `category` — ключ, `shoes` — значение
- `&` — разделитель между параметрами
- `size=42`, `color=black` — последующие параметры
Законные и полезные цели GET-параметров:
- Фильтрация и сортировка: `?sort=price_asc`, `?brand=nike&max-price=100`
- Поиск на сайте: `?q=query_string`
- Параметры сессий и отслеживания (UTM): `?sessionid=abc123`, `?utm_source=newsletter`
- Пагинация: `?page=2`
- A/B тестирование: `?variant=b`
Проблема начинается тогда, когда страница с параметрами и без них (или с разными их наборами) выдает один и тот же или очень похожий контент.
2. Почему GET-параметры создают дубли? Проблема для SEO
Представьте, у вас есть страница каталога: example.com/catalog/shoes.
Затем пользователь применяет фильтр по размеру, и URL меняется на: example.com/catalog/shoes?size=42.
Если при этом основное содержимое страницы (заголовок H1, список товаров, текст) остается практически идентичным, а меняется лишь небольшая часть (например, убрались товары не 42-го размера), для поискового робота это две разные страницы с очень похожим контентом.
Чем это опасно для SEO:
- Рассеивание сканирующего бюджета: робот Google тратит ограниченное время и ресурсы на обход вашего сайта. Вместо того чтобы индексировать 100 уникальных страниц, он может потратить силы на 500 версий одних и тех же страниц с разными параметрами.
- Размытие ссылочного веса (PageRank): если на вашу страницу `shoes` ведут внешние ссылки, а кто-то поделился ссылкой на `shoes?size=42`, то ссылочный вес распределится между этими двумя URL. Вместо концентрации на одном каноническом URL вы дробите свою силу.
- Сложность отслеживания позиций: по какому URL ранжируется страница? По основному? По версии с параметром? ПС может выбрать свою любимую версию, и вы не будете видеть точной статистики в Analytics и Search Console.
- Риск санкций за дублированный контент: прямые ручные санкции за дубли сегодня редки, но ПС просто не будет показывать в выдаче "неканоническую" версию. Ваша страница может выпасть из индекса или не попасть в него вовсе.

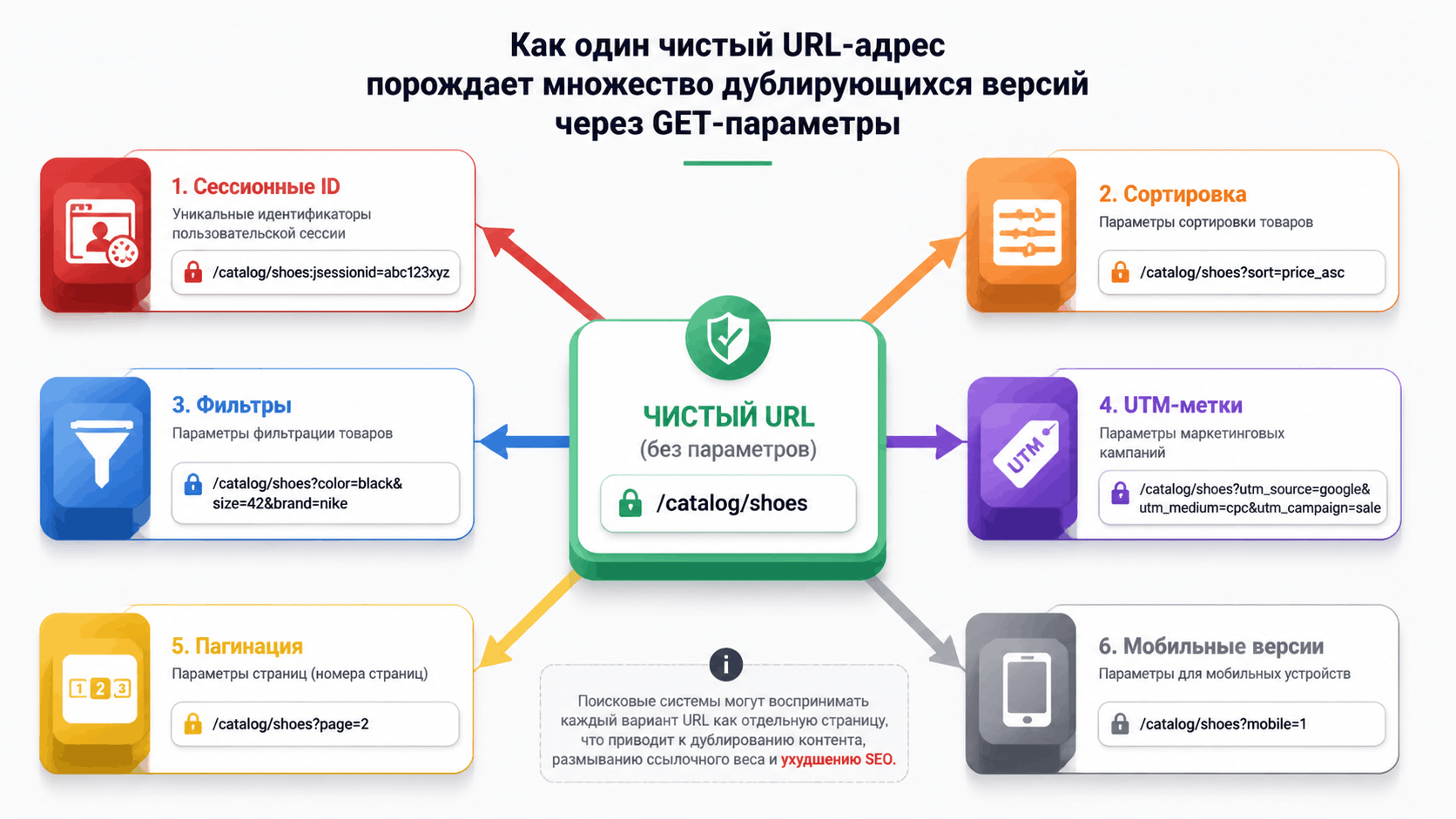
3. Типичные сценарии появления дублей через параметры
- Сессионные идентификаторы (`?sid=..., ?phpsessid=...`): самый опасный и бесполезный дубль. Каждому пользователю (и даже роботу!) присваивается уникальный ID, создавая бесконечное число дублей.
- Параметры сортировки (`?order=price`, ?`order=name`): страница одна, а URL — разные.
- Параметры фильтрации (`?color=red`, `?color=blue&size=M`): особенно если при применении одного фильтра контент меняется незначительно.
- Параметры отслеживания (UTM, `?ref=...`, `?source=...`): очень частая проблема. Пользователь заходит по рекламной ссылке `site.com/?utm_source=facebook`, сайт сохраняет этот URL в аналитике, и робот может его проиндексировать.
- Параметры пагинации (`?page=2`, `?p=2`): страницы 2,3,4... часто являются дублями друг друга по структуре, если на них нет уникального описания.
- Параметры для мобильных версий (`?mobile=1`): в эпоху адаптивного дизайна это анахронизм, но все еще встречается.
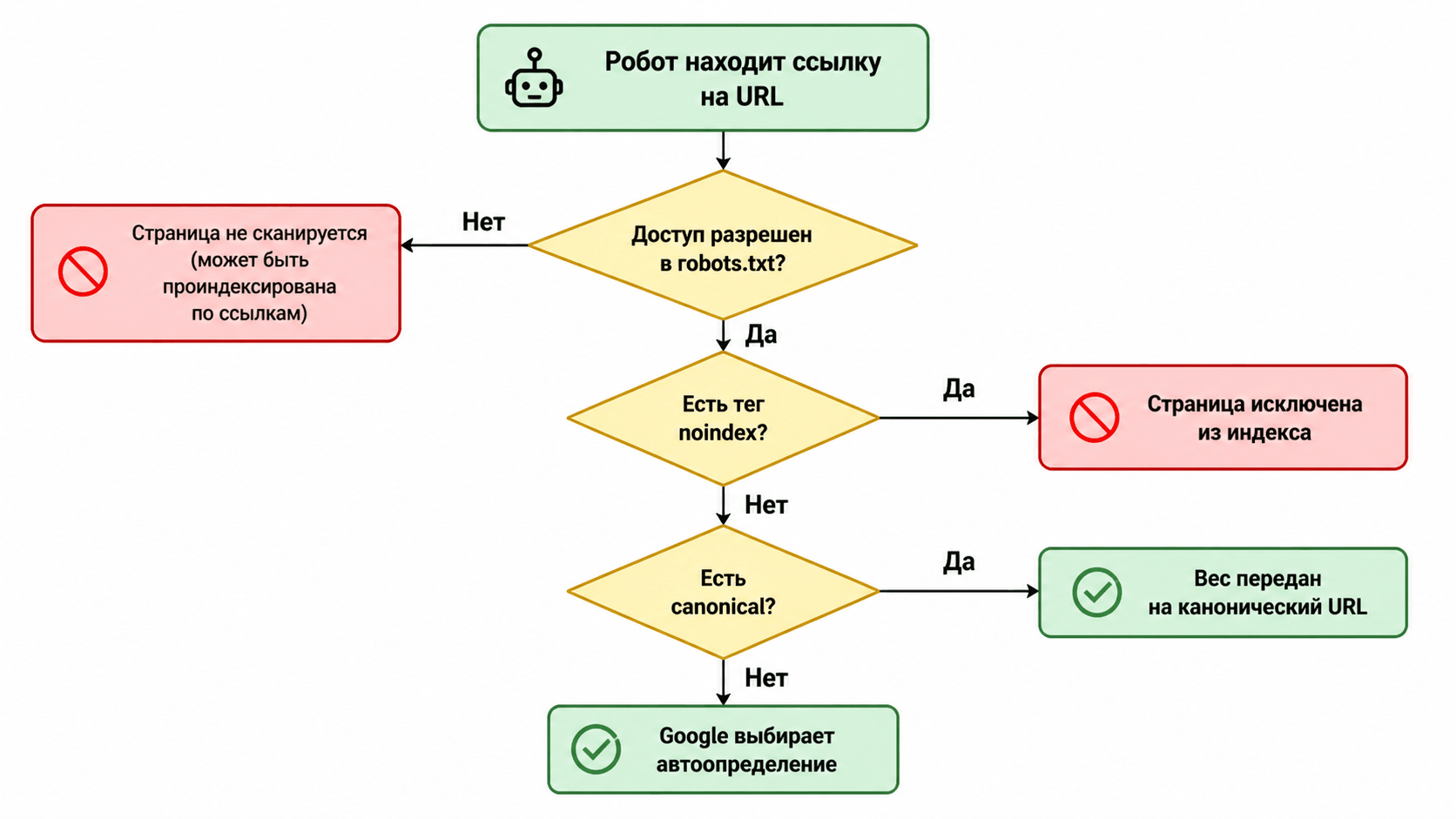
4. Как поисковые системы обрабатывают дубли?
Google стал умнее, но не всесилен. Он использует несколько стратегий:
- Выбор "канонической" версии: робот анализирует контент и внутренние ссылки и пытается сам определить, какая версия URL является главной. Он объединяет сигналы с разных URL и показывает в выдаче ту, которую посчитал основной.
- Учет директив веб-мастера: самый важный инструмент. Google приоритизирует явно указанные вами инструкции в `rel="canonical"`, robots.txt и meta-тегах.
- Аггрегация ссылочного веса: старается объединить вес ссылок, ведущих на разные URL-дубли, в пользу канонической страницы.
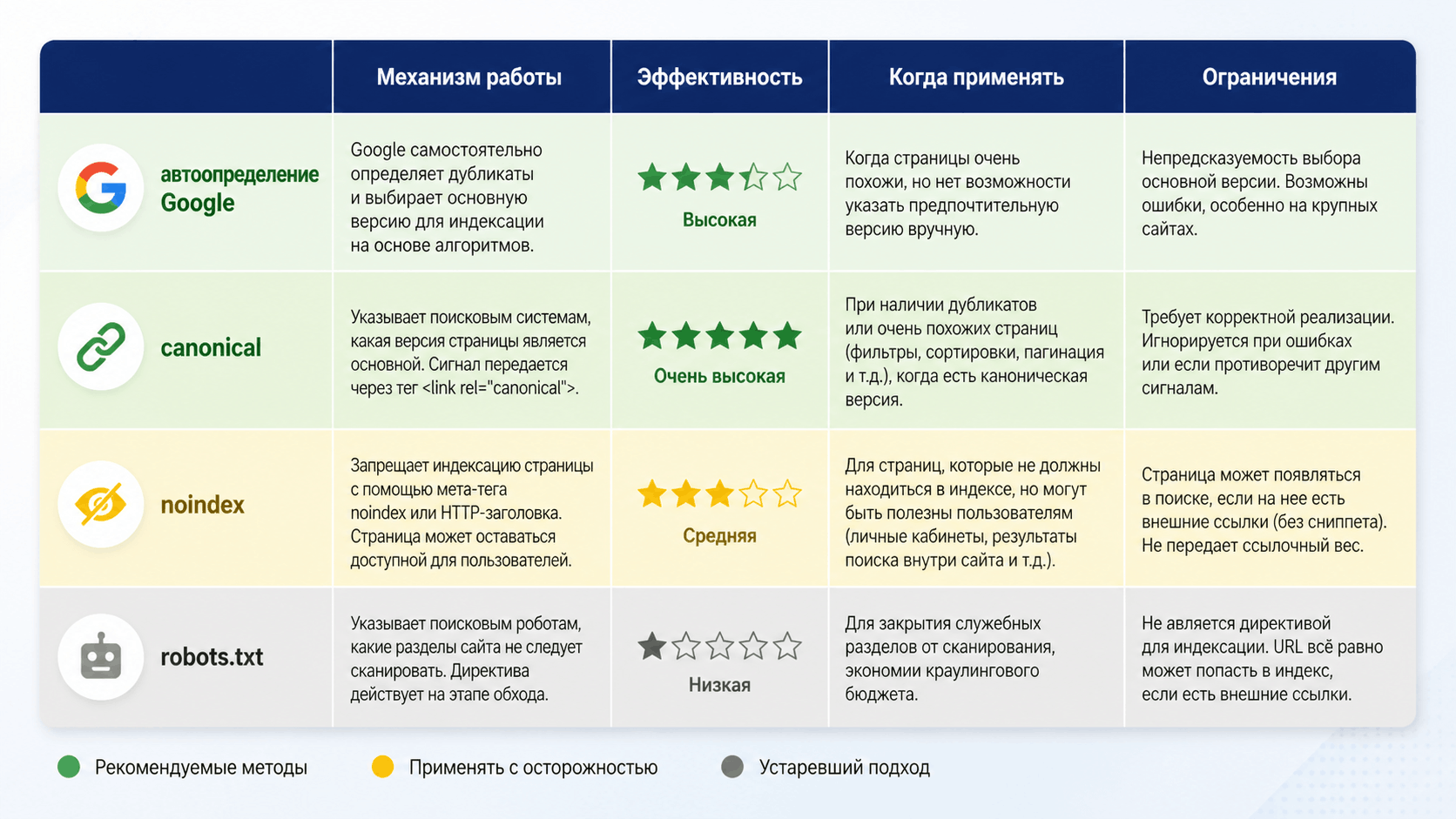
Но надеяться на "автоопределение" — большая ошибка. Вы должны явно указать ПС, как обращаться с параметрами.
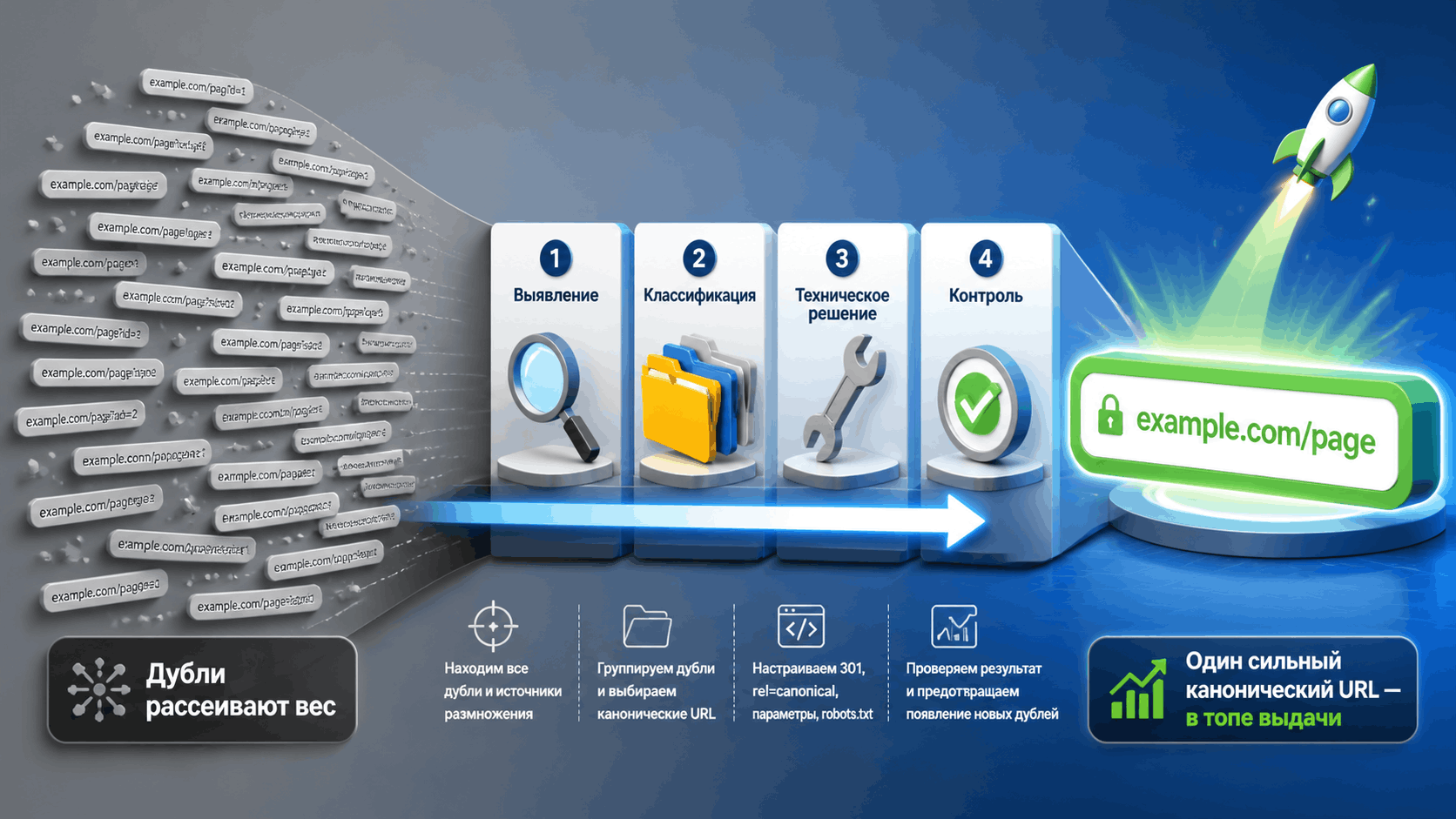
5. Пошаговый план борьбы с дублями: инструкция
Вот методология, которую я использую на проектах.
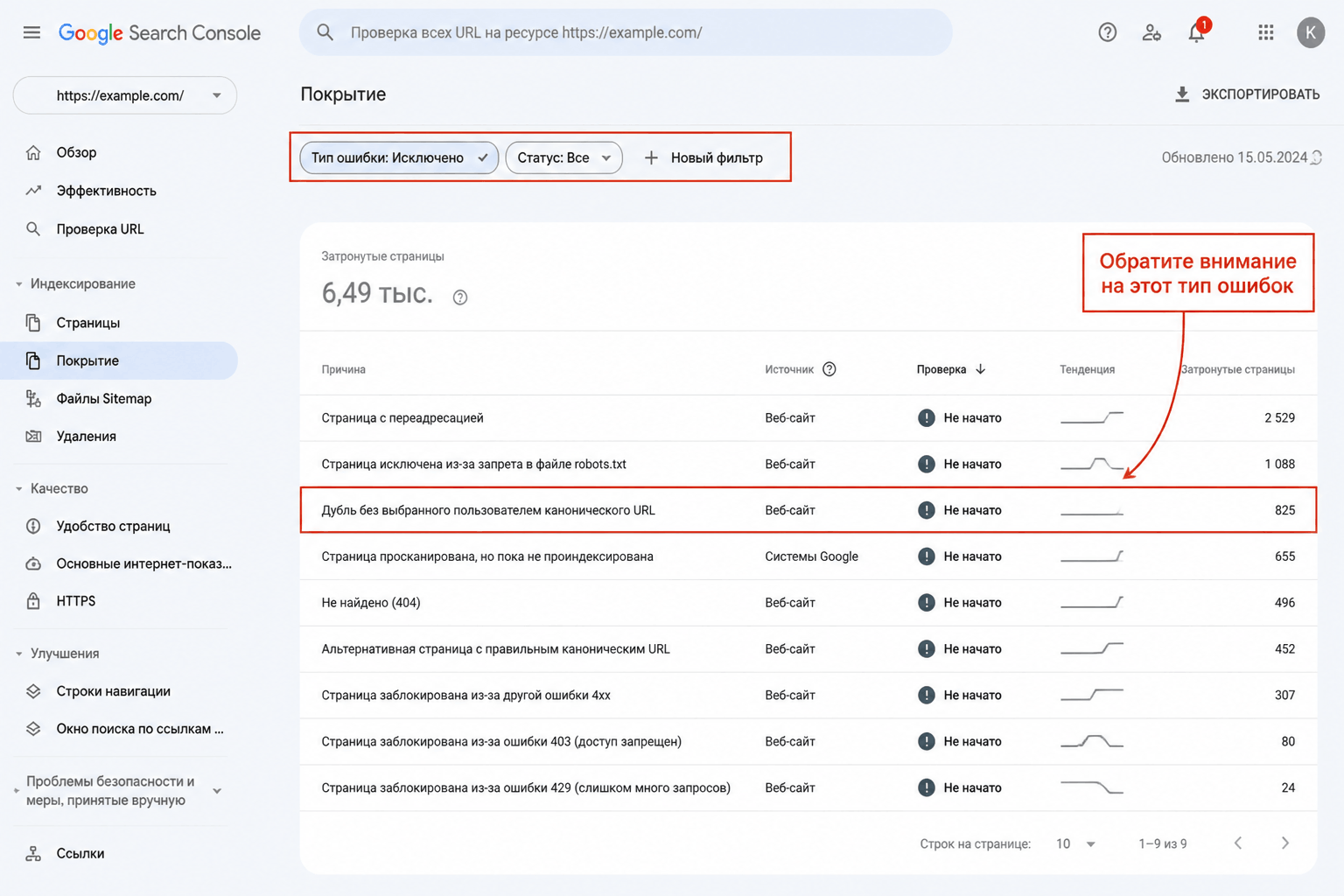
Шаг 1: выявление и инвентаризация
Соберите все возможные URL с параметрами.
- Google Search Console: отчет "Coverage" (Покрытие). Ищите ошибки "Duplicate without user-selected canonical" (Дубль без выбранного пользователем канонического URL). Отчет "URL Parameters" (Параметры URL) — сейчас он скрыт в старом интерфейсе, но если он у вас был настроен, он бесценен.
- Логи сервера: прямой источник истины. Вы увидите, какие URL с параметрами сканируют роботы.
- Краулеры (Screaming Frog, Netpeak Spider): настройте на игнорирование параметров в настройках, и он покажет вам все URL, которые он посчитал дублями. В Screaming Frog: "Configuration > Spider > Ignore Parameters".
- Аналитика поведения: посмотрите в Google Analytics, с каких URL с параметрами приходит трафик.
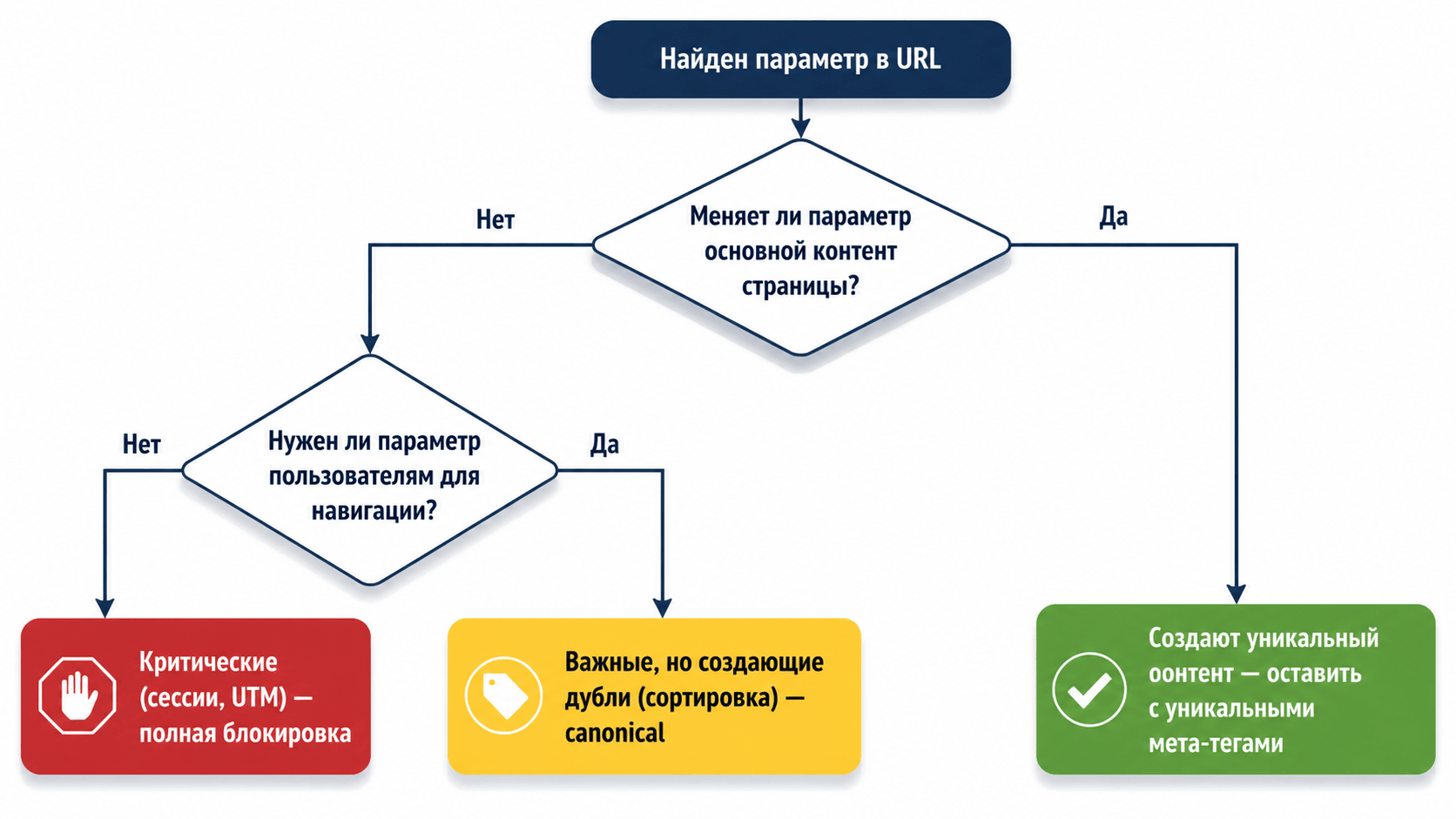
Шаг 2: анализ и классификация
Разделите все найденные параметры на три категории:
- Критические (Сессионные, UTM): не меняют контент, только служебная информация. Действие: полная блокировка индексации.
- Важные для пользователя, но создающие дубли (Сортировка, Фильтры): меняют отображение контента, но основная суть страницы та же. Действие: указание канонической версии на страницу без параметров (или с основным набором).
- Создающие уникальный контент (Глубокая фильтрация, Поиск): если страница с параметром `?category=shoes` кардинально отличается от главной страницы каталога, ее можно оставить для индексации, но обязательно прописать ей собственный канонический URL и уникальные мета-теги.
Шаг 3: реализация технических решений
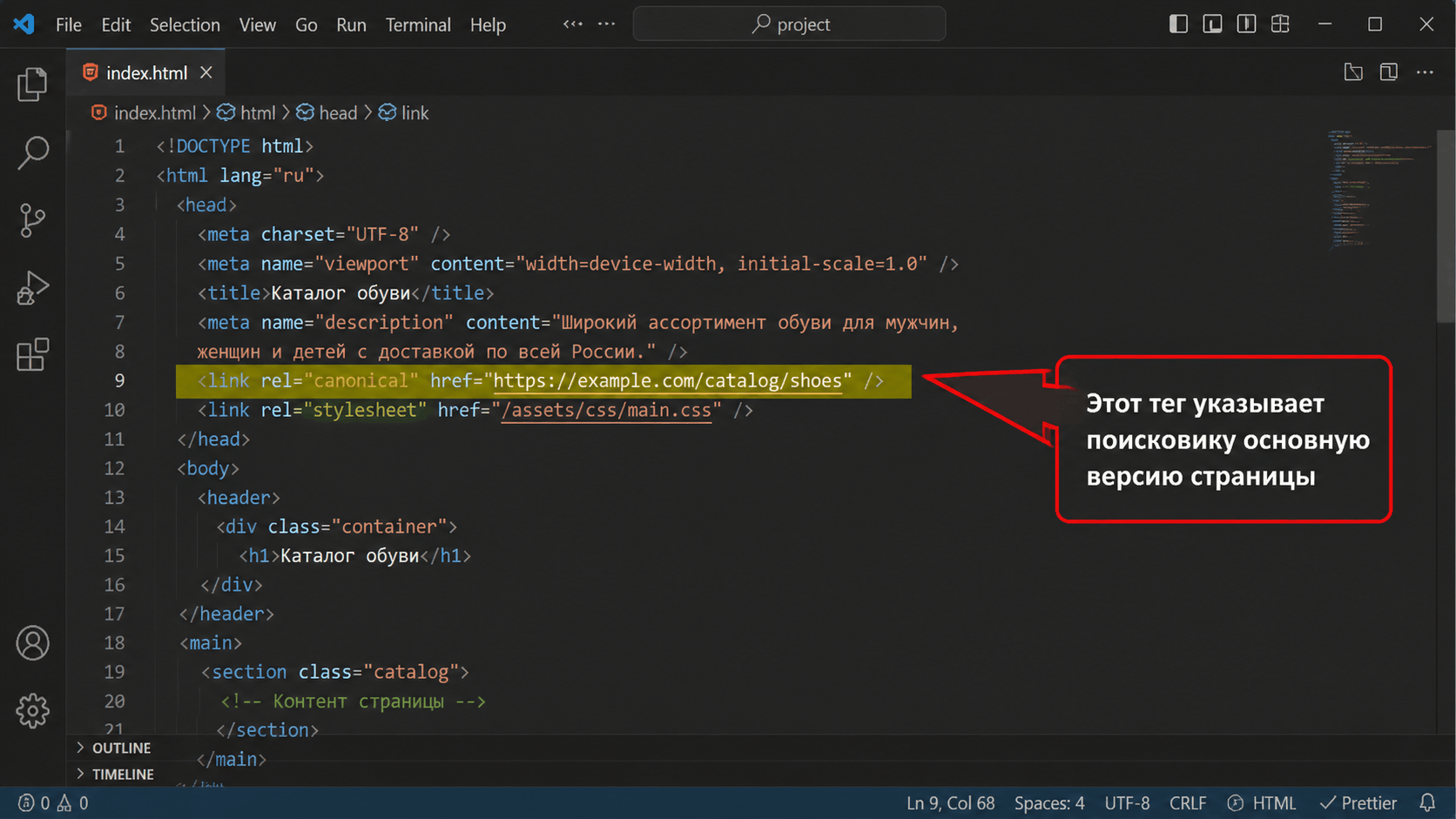
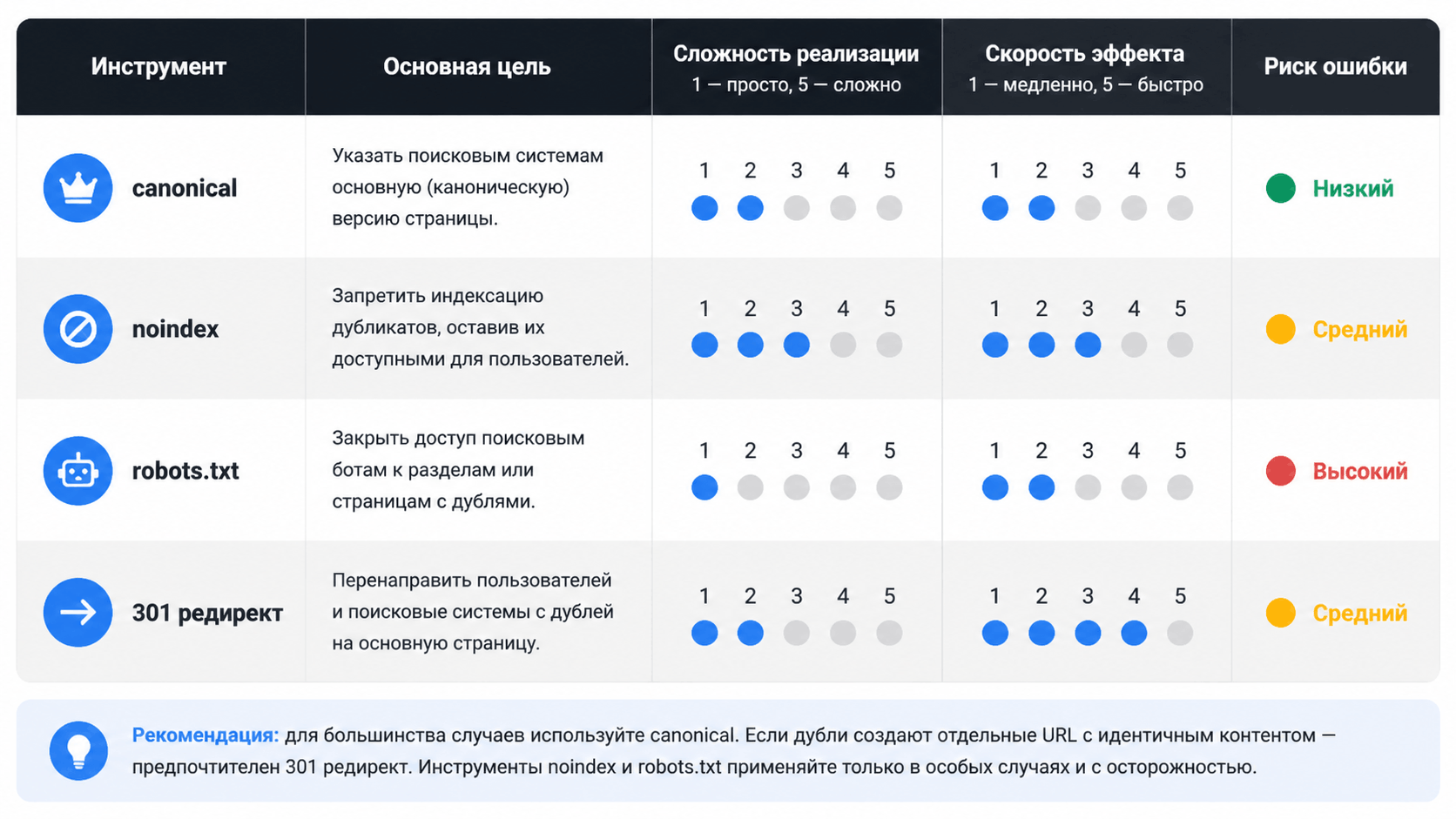
Решение №1: Тег `rel="canonical"` (самый главный инструмент)
На странице-дубле (`example.com/catalog/shoes?size=42`) в секции `
` разместите ссылку на основную (каноническую) версию.<link rel="canonical" href="https://example.com/catalog/shoes" />
Это сообщает ПС: "Эта страница — вариант вот этой основной. Учитывайте все ссылки и ранжируйте именно основную версию".
- Для пагинации: для страниц `?page=2`, `?page=3` каноническая ссылка должна вести на саму себя. Это не дубли главной страницы, это уникальные страницы списков. Но для страниц 2,3,N можно также добавить `rel="prev"` и `rel="next"`.
Решение №2: директива `noindex`
Для страниц, которые точно не должны попадать в индекс (например, результаты внутреннего поиска, корзина), используйте meta-тег роботов.
<meta name="robots" content="noindex" />
Важно: нельзя использовать `noindex` вместе с `canonical` на одной странице. `Canonical` — это мягкая рекомендация, `noindex` — жесткая команда. Команда `noindex` имеет приоритет, но такая комбинация противоречива и не рекомендуется.
Решение №3: файл `robots.txt`
Используйте для полного запрета сканирования URL с определенными параметрами. Это защищает от расхода сканирующего бюджета.
User-agent: * Disallow: /*?sort= Disallow: /*?utm_ Disallow: /*?sessionid= Disallow: /*?*&sessionid= # на случай, если параметр не первый
Внимание! запрет в `robots.txt` не позволяет роботу сканировать URL, но он может проиндексировать его, если найдет ссылку из другого места. Поэтому для полной гарантии комбинируйте с `noindex` (но для `noindex` робот должен иметь доступ к странице, чтобы увидеть тег). Идеальный вариант для "опасных" параметров — закрыть их от сканирования в `robots.txt` И прописать `canonical` на основных страницах.
Решение №4: перенаправление 301
В некоторых случаях есть смысл сделать 301-редирект со страницы с параметром на страницу без. Например, если старый URL с параметром был проиндексирован и на него есть ссылки, но по своей сути он дублирует главную. Это на 100% объединяет ссылочный вес.
Решение №5: управление через Google Search Console (устаревший, но может работать)
В старом интерфейсе GSC был раздел "Параметры URL", где можно было указать Google, как обрабатывать разные типы параметров. Сейчас этот функционал не рекомендуется к использованию, так как Google заявляет, что хорошо справляется с автоопределением. Полагайтесь на код, а не на настройки в GSC.
Шаг 4: работа со внутренними ссылками
Убедитесь, что в самой структуре сайта (меню, хлебные крошки, блоки "Похожие товары") вы ссылаетесь только на канонические URL без лишних параметров. Не заставляйте робота ползти по ссылке `site.com/catalog/?from=menu`.
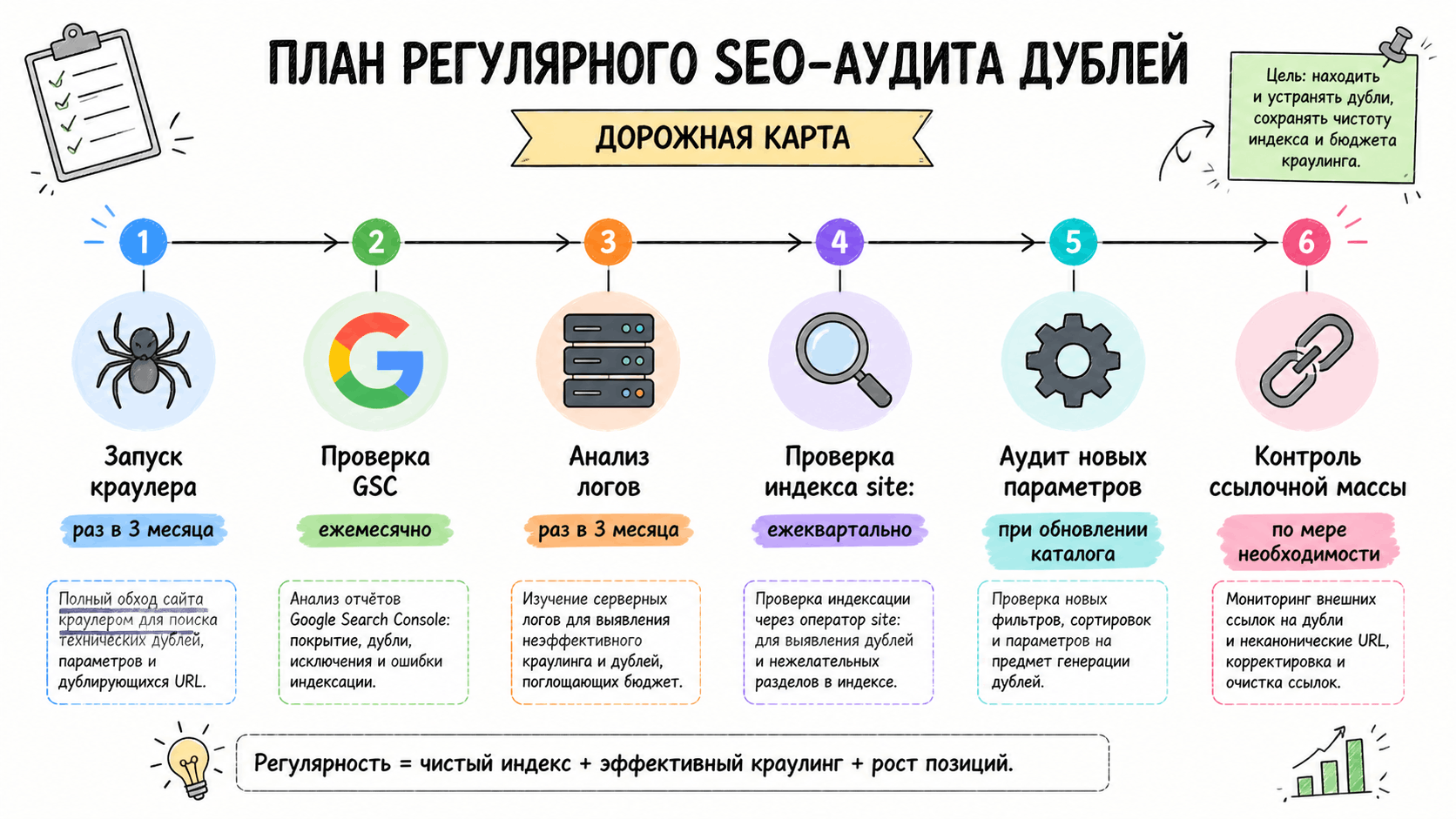
6. Чек-лист: профилактика и регулярный аудит
Профилактика:
- При разработке сайта сразу определите, какие параметры будут меняют контент, а какие — нет.
- Для всех служебных параметров (UTM, сессии) по умолчанию настройте `rel="canonical".
- Избегайте использования GET-параметров для идентификации основных страниц. Используйте ЧПУ (Человекопонятные URL): не `site.com?category=1`, а `site.com/catalog/shoes/`.
- Настройте корректную обработку UTM-меток в системах аналитики, чтобы они не влияли на отслеживание URL в отчетах.
Регулярный аудит (раз в 3-6 месяцев):
- Запустите краулер (Screaming Frog) с игнорированием нужных параметров и проверьте отчет по дублям.
- Изучите отчет "Coverage" в Google Search Console.
- Просмотрите логи сервера на предмет сканирования "странных" URL роботами.
- Проверьте, нет ли в индексе Google (через оператор `site:example.com ?utm_`) проиндексированных служебных URL.
Заключение
Проблема дублей из-за GET-параметров — это не катастрофа, а рутинная техническая работа. Ключ к успеху — в системном подходе: выявить, классифицировать, применить корректное техническое решение и контролировать.
Помните: ваша цель — не просто убрать дубли из индекса, а направить весь вес и все сигналы на одну, сильную, каноническую версию каждой страницы. Это очищает сканирующий бюджет, укрепляет SEO-профиль и дает вам четкую картину для дальнейшей работы над продвижением.
Удачи в работе! Если остались вопросы — вы знаете, где меня найти.
Почему я не закрываю глаза на «технические мелочи»?
Ваш сайт теряет до 60% трафика из-за невидимых проблем. Я устраняю их так, чтобы вы заметили рост позиций уже через месяц, без риска для текущего рейтинга.
Возражения экспертного уровня: как я решаю то, что другие считают «нормой»?
В моей работе с любым проектом я постоянно сталкиваюсь с одними и теми же сомнениями. Я не просто даю стандартные ответы — я раскрываю истинные причины вашего беспокойства и показываю путь, который ведет к измеримому результату.
Я уже не раз доказывал, что размер ресурса не имеет значения, когда речь идет о сканирующем бюджете. Даже для сайта с 30–50 страницами наличие технических дублей означает, что поисковые системы тратят свой «лимит внимания» на мусор. В результате ваши ключевые посадочные страницы получают меньше внимания, чем могли бы. Я точечно настраиваю канонические ссылки, чтобы каждый визит робота приносил пользу именно вашим основным разделам. После моей доработки вы не просто увидите улучшение индексации — вы почувствуете, как трафик начинает приходить на те страницы, которые действительно приносят заявки.
Да, алгоритмы стали совершеннее, но они не читают ваши бизнес-задачи. В более чем 40% случаев автоматический выбор поисковика не совпадает с тем, что выгодно именно вам. Я не полагаюсь на случай — я сам указываю приоритеты через четкую структуру URL, правильные редиректы и метатеги. Это как если бы вы не надеялись, что навигатор сам догадается, куда вы хотите ехать, а заранее прокладывали маршрут. В результате вы получаете полный контроль над тем, какая версия страницы попадает в топ, а не довольствуетесь тем, что «решил» робот.
Я ценю ваше время, поэтому базовая настройка canonical и robots.txt занимает не более 3 часов моей работы. При этом эффект начинает проявляться уже через 14–20 дней. Вы не закапываетесь в программирование — вы получаете готовое решение, которое сразу начинает работать на ваш бизнес. Более того, я поэтапно внедряю изменения, чтобы вы видели промежуточные результаты и могли корректировать стратегию без остановки текущих процессов. Это не «проект на полгода», а точечное вмешательство с высокой отдачей.
Я не предлагаю убрать аналитику — я предлагаю правильно ее организовать. Все служебные метки остаются в вашей системе учета, но я делаю так, чтобы они не влияли на основной индекс поисковиков. Это похоже на то, как если бы вы вели бухгалтерию в отдельных папках, не смешивая их с витриной магазина. Я настраиваю обработку параметров на уровне аналитических платформ, сохраняя все данные о источниках трафика. В итоге вы получаете и чистый сайт для поисковых систем, и полную статистику по каждому каналу привлечения.
Уникальность контента не отрицается. Если страницы действительно разные, они должны жить своей жизнью — со своими заголовками, описаниями и каноническими ссылками на самих себя. Я не «склеиваю» все подряд, а провожу аудит и определяю, где параметр создает истинно новую сущность, а где — просто копию с незначительными изменениями. В первом случае я оставляю всё как есть, но с правильной структурой. Во втором — объединяю вес на главную версию. Такой подход позволяет сохранить все релевантные страницы в индексе, не размывая их ценность для поиска.
Я понимаю ваше разочарование. Часто проблема не в самом методе, а в его неполной реализации. Мало просто прописать тег — нужно убедиться, что нет конфликтующих директив в robots.txt, не дублируются ли заголовки и не переопределяет ли CMS ваши настройки. Я провожу комплексную диагностику: проверяю цепочки редиректов, анализирую логи сервера и смотрю, как именно поисковик интерпретирует ваши указания. После моей настройки вы получаете не просто строчку в коде, а работающий механизм, который действительно перенаправляет сигналы ранжирования туда, куда нужно.
Простота — это хорошо, но только когда она не вредит делу. Запрет всех параметров в robots.txt — это как закрыть вход в магазин, чтобы не было пыли. Да, пыли станет меньше, но и покупатели не зайдут. Я не перекрываю доступ к функциональным страницам (фильтрам, сортировке, пагинации), которые могут быть полезны для пользователей. Вместо этого я выборочно настраиваю индексацию: служебные параметры прячу, а рабочие — оставляю с правильными атрибутами. Так вы не теряете ни один потенциальный визит и при этом избавляетесь от мусора в индексе.
Дубли страниц — это не мгновенный удар, а медленное обесценивание. Вы можете не замечать падения позиций месяцами, но при этом ваш ссылочный вес распыляется, а релевантность страниц снижается. Я показываю вам не только текущее состояние, но и прогноз: сколько трафика вы теряете прямо сейчас из-за того, что робот тратит время на обход десятков одинаковых версий одной страницы. После моего вмешательства вы видите не резкий скачок, а устойчивый рост органического трафика на 20–40% в течение 1,5–2 месяцев. Это не косметика — это работа с фундаментом вашего присутствия в сети.
Отвечаю на самые сложные вопросы о дублях и параметрах
Вы получаете не просто теорию, а готовые решения для каждого сценария — от интернет-магазина до корпоративного портала, с понятными сроками и измеримыми результатами
В своей практике я сталкиваюсь с одними и теми же сомнениями снова и снова. Ниже я собрал наиболее частые из них и дал на них развернутые ответы, которые помогут вам принять верное решение без погружения в технические дебри.
Когда поисковая система обнаруживает несколько версий одной страницы, она распределяет свой «вес» между ними. Представьте, что у вас есть десять одинаковых витрин в разных частях города, и вы развозите рекламные листовки поровну между ними. Ни одна витрина не получит достаточно внимания, чтобы стать по-настоящему заметной. То же самое происходит с вашим сайтом: ссылочный вес распыляется, а релевантные сигналы теряются.
Я решаю эту проблему, консолидируя все сигналы на одной основной странице. После моей настройки вы замечаете, что ключевые запросы начинают уверенно подниматься в выдаче, а на сайт приходит больше целевых посетителей именно с тех слов, которые ведут к покупке. Это не магия — это правильное перераспределение ресурсов.
Я прекрасно понимаю эту боль. Именно поэтому я не предлагаю вручную прописывать канонические ссылки для каждой товарной позиции. Вместо этого я использую автоматизированные подходы на уровне архитектуры сайта:
- Настраиваю шаблоны, которые определяют основную версию страницы и автоматически проставляют правильные атрибуты.
- Для фильтров и сортировок внедряю специальные правила: например, первая страница с параметрами становится главной, а все последующие — дочерними с указанием правильной связи.
- Для товаров с одинаковым описанием, но разными артикулами я предлагаю создавать сводные карточки или настраивать редиректы с наиболее слабых страниц на сильные.
Это абсолютно здоровый подход. Я всегда начинаю с тщательного аудита и создаю резервную копию всех текущих настроек. Любое изменение я внедряю поэтапно:
- Сначала на тестовом поддомене или в изолированной среде.
- Затем на небольшой группе страниц, чтобы оценить влияние.
- И только после подтверждения положительной динамики — масштабирую на весь сайт.
Я рекомендую проводить плановый аудит технической структуры не реже одного раза в квартал. Но я иду дальше — я настраиваю систему автоматического оповещения, которая сигнализирует, когда количество дублей начинает превышать допустимый порог. Это похоже на регулярное ТО автомобиля: вы не ждете, пока двигатель застучит, а проводите профилактику, чтобы избежать серьезных поломок.
После моей первичной настройки вы получаете подробную инструкцию по самостоятельному контролю, а также можете рассчитывать на мою поддержку при масштабных обновлениях каталога. Так вы всегда будете уверены, что ваш сайт находится в оптимальном техническом состоянии.
Да, UTM-метки и другие служебные параметры необходимы, но их не должно быть в основном индексе. Я предлагаю простое и элегантное решение:
- Настраиваю игнорирование служебных параметров на уровне поисковых систем через специальные инструменты (например, в Google Search Console есть раздел для настройки обработки URL-параметров).
- Все метки остаются видны для ваших систем аналитики, но не создают дублирующих страниц в глазах роботов.
- Для ссылок из социальных сетей и рекламных кампаний я использую 301-редирект с параметром на чистую версию страницы, сохраняя все данные о переходе.
Фильтры — это инструмент навигации. Когда пользователь выбирает фильтр (например, «размер 42»), он получает подборку товаров. Если эти страницы имеют уникальный контент и мета-теги, они могут быть самостоятельными посадочными страницами. Сортировка (по цене, популярности) обычно не создает нового смыслового содержания — это просто перестановка одних и тех же товаров.
Мой подход:
- Для фильтров я рекомендую создавать отдельные URL с самостоятельными каноническими ссылками, если они приносят целевой трафик. Например, «футболки красные» — это уже почти отдельная категория.
- Для сортировки я устанавливаю параметр
rel="nofollow"для ссылок и добавляю мета-тегnoindexна страницы с сортировкой, чтобы они не попадали в индекс.
Я часто слышу эту фразу, и мой опыт показывает, что за ней скрывается не техническая сложность, а нежелание менять устоявшиеся процессы. Моя задача — показать разработчикам, что изменения не потребуют полной перестройки архитектуры.
Я подхожу к вопросу прагматично:
- Разрабатываю пошаговый план внедрения, который не нарушает работу текущих модулей.
- Использую существующие возможности вашей CMS или фреймворка — часто правильная настройка уже есть в стандартном функционале, просто никто ею не пользовался.
- Документирую все изменения и предоставляю четкие инструкции, чтобы ваша команда могла легко поддерживать новую структуру.
Я предлагаю говорить на языке бизнеса, а не технических терминов. Вместо «канонические ссылки» и «роботы» используйте понятные метрики:
- Доля потерянного трафика. Я показываю, сколько посетителей могли бы приходить на сайт, если бы дубли не отвлекали на себя внимание роботов. Я рассчитываю эту цифру на основе данных из Google Search Console и серверных логов.
- Скорость индексации новых страниц. После настройки вы быстрее попадаете в выдачу с новыми товарами или акциями, а значит, быстрее получаете заказы.
- Экономия рекламного бюджета. Если органический трафик растет, вы можете сократить расходы на контекстную рекламу при сохранении общего числа лидов.
Профессиональная SEO-оптимизация включает не только работу с контентом, но и техническую корректность сайта.
устранение дублей — один из самых эффективных способов улучшить видимость без создания нового контента.
Полный справочник GET-параметров с рекомендациями по обработке
⚠️ Важное замечание
Не все параметры нужно блокировать! Рекомендуемый подход:
- Блокировать (robots.txt): только параметры отслеживания и сессии, не влияющие на контент
- Использовать canonical: для параметров, которые создают дубли (фильтры, сортировка) или меняют представление
- Индексировать: параметры, которые кардинально меняют содержание страницы (язык, регион, уникальные фильтры)
Анализ недостающих параметров
Из предоставленного списка Clean-param в вашем текущем справочнике отсутствуют следующие параметры:
| Параметр | Категория | Рекомендация | Описание |
|---|---|---|---|
ctime | Время/Кэш | Блокировать | Время создания/кэширования |
etext | Контент | Canonical | Текстовый параметр (возможно для поиска) |
gtm_latency | Аналитика | Блокировать | Google Tag Manager latency |
keys | Поиск | Canonical | Ключи поиска (синоним keywords) |
parent-baobab-id | Внутренние | Блокировать | Внутренний ID Яндекса |
parent-reqid | Внутренние | Блокировать | Родительский request ID |
sort_by | Сортировка | Canonical | Сортировка по полю |
src_pof | Источник | Блокировать | Source POF (платформа) |
tag | Контент | Canonical | Тег/категория контента |
cm_id | Маркетинг | Блокировать | Campaign Manager ID |
yklid | Аналитика | Блокировать | Yandex Klik ID |
type | Контент | Canonical | Тип контента/страницы |
sbclid | Аналитика | Блокировать | Source Click ID |
icliyd | Аналитика | Блокировать | Internal Click ID (Yandex) |
cx | Поиск | Блокировать | Custom Search Engine ID (Google) |
iclyd | Аналитика | Блокировать | Internal Click Yandex |
icllcd | Аналитика | Блокировать | Internal Click Location Code |
yklld | Аналитика | Блокировать | Yandex Klik Location |
ykild | Аналитика | Блокировать | Yandex Klik Internal |
ykilt | Аналитика | Блокировать | Yandex Klik Internal Time |
ykilp | Аналитика | Блокировать | Yandex Klik Internal Position |
yqilp | Аналитика | Блокировать | Yandex Query Internal Position |
yqipl | Аналитика | Блокировать | Yandex Query Internal Page Load |
yqpil | Аналитика | Блокировать | Yandex Query Page Internal |
yaqpil | Аналитика | Блокировать | Yandex Advanced Query Page Internal |
yclud | Аналитика | Блокировать | Yandex Click User Data |
ybqpil | Аналитика | Блокировать | Yandex Browser Query Page Internal |
ypppil | Аналитика | Блокировать | Yandex Partner Page Internal |
clckid | Аналитика | Блокировать | Click ID (общий) |
yqppel | Аналитика | Блокировать | Yandex Query Partner Page Element |
yprqee | Аналитика | Блокировать | Yandex Partner Request Element |
block | Контент | Canonical | Блок/секция контента |
position | Контент | Canonical | Позиция элемента |
ypppel | Аналитика | Блокировать | Yandex Partner Page Position Element |
yycleed | Аналитика | Блокировать | Yandex Yandex Click Element |
ycllcd | Аналитика | Блокировать | Yandex Click Location Code |
ylecd | Аналитика | Блокировать | Yandex Location Element Code |
yhyd | Аналитика | Блокировать | Yandex Host Yandex Data |
yiclyd | Аналитика | Блокировать | Yandex Internal Click Yandex Data |
erid | Реклама | Блокировать | External Reference ID |
added | Контент | Canonical | Добавленный элемент |
loadme | Технические | Блокировать | Флаг загрузки |
device | Устройства | Canonical | Тип устройства |
region_name | Гео | Индексировать | Название региона |
category_id | Контент | Canonical | ID категории |
limit | Пагинация | Canonical | Лимит элементов |
target | Контент | Canonical | Целевой элемент |
Итого: в вашем списке отсутствовало 48 параметров из предоставленного Clean-param. Большинство из них — параметры аналитики Яндекса и внутренние идентификаторы.
Аналитика и отслеживание
Параметры, используемые системами аналитики и отслеживания. Не влияют на контент, следует блокировать.
Сессионные параметры
Параметры сессий и временные идентификаторы. Не влияют на контент, следует блокировать.
Поиск, фильтрация и сортировка
Важно: Для поиска и базовой сортировки - использовать canonical. Для уникальных фильтров (цвет, размер) - можно индексировать.
Языки, локали и регионы
Параметры, меняющие язык или региональные настройки. Это уникальный контент, следует индексировать.
Пагинация и навигация
Параметры пагинации. Использовать canonical на первую страницу + rel="prev/next".
Контентные параметры
Параметры, меняющие отображение контента. Использовать canonical на основную версию.
Источники и рефералы
Параметры источников трафика. Использовать canonical на основную страницу.
Технические параметры, кэш и время
Параметры для управления кэшем и временем. Не влияют на контент, следует блокировать.
Внутренние и системные параметры
Внутренние идентификаторы систем. Не для индексации.
Параметры устройств
Параметры для разных типов устройств. Использовать canonical на десктопную версию.
Сводная таблица рекомендаций по обработке параметров
| Категория | Рекомендуемая обработка | Примеры параметров | Причина |
|---|---|---|---|
| Аналитика Яндекса | Блокировать | yklid, icliyd, iclyd, ycllcd, ylecd | Внутренние параметры отслеживания Яндекса |
| Внутренние ID | Блокировать | parent-baobab-id, parent-reqid | Внутренние системные идентификаторы |
| Контентные фильтры | Canonical | type, tag, category_id, block | Меняют отображение, но не основное содержание |
| Технические | Блокировать | ctime, gtm_latency, loadme | Параметры кэша и производительности |
| Географические | Индексировать | region, region_name | Создают уникальный гео-контент |
Рекомендуемая реализация для новых параметров
Стратегия для новых параметров:
- Все Яндекс-аналитика параметры (yklid, icliyd, ycllcd и т.д.) - блокировать
- Внутренние ID (parent-baobab-id, parent-reqid) - блокировать
- Контентные параметры (type, tag, category_id) - canonical
- Гео-параметры (region, region_name) - индексировать
Обновленный robots.txt с новыми параметрами
User-agent: * # Блокируем Яндекс аналитику и внутренние параметры Disallow: /*?*yklid=* Disallow: /*?*icliyd=* Disallow: /*?*iclyd=* Disallow: /*?*icllcd=* Disallow: /*?*ycllcd=* Disallow: /*?*ylecd=* Disallow: /*?*yhyd=* Disallow: /*?*yiclyd=* Disallow: /*?*yklld=* Disallow: /*?*ykild=* Disallow: /*?*ykilt=* Disallow: /*?*ykilp=* Disallow: /*?*yqilp=* Disallow: /*?*yqipl=* Disallow: /*?*yqpil=* Disallow: /*?*yaqpil=* Disallow: /*?*yclud=* Disallow: /*?*ybqpil=* Disallow: /*?*ypppil=* Disallow: /*?*yqppel=* Disallow: /*?*yprqee=* Disallow: /*?*ypppel=* Disallow: /*?*yycleed=* # Блокируем внутренние системные параметры Disallow: /*?*parent-baobab-id=* Disallow: /*?*parent-reqid=* Disallow: /*?*cm_id=* Disallow: /*?*erid=* # Блокируем технические параметры Disallow: /*?*ctime=* Disallow: /*?*gtm_latency=* Disallow: /*?*loadme=* # Блокируем стандартную аналитику Disallow: /*?*utm_* Disallow: /*?*gclid=* Disallow: /*?*fbclid=* Disallow: /*?*yclid=* Disallow: /*?*yclod=* Disallow: /*?*yclad=* Disallow: /*?*sbclid=* # Разрешаем всё остальное Allow: /*?* Allow: /*
Примеры HTML-разметки для контентных параметров
Для страницы с типом контента:
<!-- example.com/articles?type=news --> <link rel="canonical" href="https://example.com/articles/" />
Для страницы с тегом:
<!-- example.com/blog?tag=seo --> <link rel="canonical" href="https://example.com/blog/" />
Для региона (индексировать):
<!-- example.com/services?region=moscow --> <link rel="canonical" href="https://example.com/services/?region=moscow" /> <meta name="description" content="Услуги в Москве" />
Важные выводы по новым параметрам
- Большинство новых параметров - Яндекс-аналитика: 80% отсутствовавших параметров - это различные варианты Яндекс Click ID и внутренних идентификаторов
- Все Яндекс-параметры нужно блокировать: они используются только для отслеживания и не влияют на контент
- Проверьте на своем сайте: используйте поиск по логам или аналитике, чтобы найти, какие из этих параметров реально используются на вашем сайте
- Не блокируйте региональные параметры: параметры like region и region_name могут создавать ценный гео-контент
Рекомендуется добавить все недостающие параметры в ваш основной справочник и настроить соответствующие правила в robots.txt.
Подробнее о том, какие GET-параметры категорически запрещено добавлять в clean-param или disallow
Опасность необдуманного управления параметрами
Я сталкивался с множеством случаев, когда неправильная настройка обработки GET-параметров приводила к катастрофическим последствиям для видимости сайта. Директивы clean-param в robots.txt и настройки disallow для параметризованных URL — это мощный инструмент, но обращаться с ним нужно как с хирургическим скальпелем: точно и осознанно.
Ошибочное добавление параметров в запрещающие директивы может привести к исчезновению из индекса критически важных страниц, потере трафика и даже к полной деиндексации разделов сайта. В этой статье я детально разберу, какие параметры никогда не стоит блокировать, почему это опасно, и как принимать взвешенные решения.
Оглавление
- Что такое clean-param и disallow для параметров?
- Категорически запрещенные к добавлению параметры
- Параметры, которые часто можно добавлять (с осторожностью)
- Методика анализа перед добавлением параметра
- Реальные кейсы из практики
- Инструменты для мониторинга и контроля
- Заключение: главные принципы безопасной работы
Что такое clean-param и disallow для параметров?
Краткое техническое объяснениеДиректива clean-param в файле robots.txt указывает поисковым системам (в основном Яндекс), что определенные GET-параметры не влияют на содержание страницы. Например:
Clean-param: ref /some_dir/*.html
Это говорит роботу: "Параметр ref в URL вида /some_dir/*.html не меняет контент, не индексируй разные варианты с этим параметром".
Директива Disallow с параметрами в URL блокирует индексацию конкретных параметризованных страниц:
Disallow: /*?session_id=
В Google аналогичного поведения можно добиться через параметры в Google Search Console или с помощью канонических ссылок.
ВНИМАНИЕ: неправильное использование этих директив может привести к необратимым последствиям для индексации вашего сайта. Всегда анализируйте перед внедрением!
КАТЕГОРИЧЕСКИ ЗАПРЕЩЕННЫЕ К ДОБАВЛЕНИЮ ПАРАМЕТРЫ
1. Параметры категорий и фильтров в интернет-магазинахПримеры:
?category=?cat_id=?brand=?price_from=/?price_to=?size=?color=?sort=(если сортировка влияет на выдачу товаров)
Почему нельзя блокировать:
Эти параметры создают уникальный контент. Страница site.ru/catalog?category=shoes и site.ru/catalog?category=hats — это разные страницы с разным содержанием. Блокировка приведет к тому, что:
- Не будут проиндексированы категории товаров
- Потеряется целевой трафик по коммерческим запросам
- Упадут конверсии
Исключение: параметры сортировки, которые не меняют набор товаров, а только их порядок (если это чисто клиентская сортировка), иногда можно добавлять в clean-param, но с осторожностью.
Примеры:
?page=?p=?pagenum=?from=
Почему нельзя блокировать:
Пагинация — это механизм навигации по последовательному контенту. Страница news?page=1 и news?page=2 содержат разные статьи. Блокируя параметр пагинации, вы:
- Останавливаете индексацию контента beyond первой страницы
- Нарушаете внутреннюю перелинковку
- Создаете проблемы с краулинговым бюджетом
Правильный подход: Используйте rel="next"/"prev" или канонические ссылки на первую страницу для бесконечной прокрутки.
Примеры:
?id=?product_id=?article_id=?news_id=
Почему нельзя блокировать:
Это самые опасные параметры для блокировки. Они часто являются основным способом доступа к уникальному контенту. Например:
site.ru/product.php?id=123— конкретный товарsite.ru/article.php?id=456— конкретная статья
Блокировка ?id= через disallow может привести к полной деиндексации всего каталога товаров или статей.
Примеры:
?q=?query=?search=?keyword=
Почему нельзя блокировать:
Внутренний поиск сайта может создавать страницы с уникальным контентом, особенно если:
- Это поиск по товарам с фильтрацией
- Поиск по статьям с релевантными результатами
- Страницы результатов поиска хорошо оптимизированы
Однако здесь нужен анализ: если поиск создает тонны низкокачественных дублей — возможно, потребуется осторожная настройка.
5. Параметры языков и регионовПримеры:
?lang=?language=?region=?country=?currency=
Почему нельзя блокировать:
Эти параметры создают географически или лингвистически таргетированный контент. Блокировка приведет к:
- Невозможности индексации мультиязычной версии сайта
- Потере международного трафика
- Проблемам с hreflang-разметкой
Примеры:
?sid=?sessionid=?phpsessid=
Здесь сложная ситуация:
С одной стороны, сессионные параметры создают дубли страниц и расходуют краулинговый бюджет. С другой — их полная блокировка через disallow может помешать индексации, если поисковый робот получит URL с сессией.
Правильный подход:
- По возможности избавиться от сессионных параметров в URL (перейти на cookies)
- Использовать
clean-paramдля Яндекс - Для Google — настройка в Search Console + канонические ссылки
- Никогда не использовать
Disallow: /*?sid=— это может заблокировать ВСЕ страницы, если робот перейдет по ссылке с сессией
Примеры:
?utm_source=?utm_medium=?utm_campaign=?ref=
Почему обычно нельзя полностью блокировать:
Хотя UTM-параметры не должны влиять на контент, их блокировка через disallow опасна:
- Робот может начать с URL с UTM и заблокировать основную страницу
- Лучше использовать
clean-paramдля Яндекса - Для Google — настройка "Игнорируемые параметры" в Search Console
ПАРАМЕТРЫ, КОТОРЫЕ ЧАСТО МОЖНО ДОБАВЛЯТЬ (с осторожностью)
Для полноты картины упомяну параметры, которые часто безопасно добавлять в clean-param:
- Параметры отслеживания:
?fbclid=,?gclid=(но только если у вас настроены другие методы отслеживания) - Параметры кеширования:
?timestamp=(если они не меняют контент) - Параметры социальных сетей:
?fb_action_ids= - Параметры порядка сортировки:
?order=(если это чисто визуальная сортировка без изменения набора элементов)
МЕТОДИКА АНАЛИЗА ПЕРЕД ДОБАВЛЕНИЕМ ПАРАМЕТРА В CLEAN-PARAM ИЛИ DISALLOW
Шаг 1: аудит существующих параметров- Соберите все URL с параметрами через лог-файлы или инструменты аналитики
- Сгруппируйте параметры по типап
- Проанализируйте, сколько уникальных значений у каждого параметра
Проверка влияния на контент: откройте одну и ту же страницу с параметром и без него. Меняется ли:
- HTML-код (кроме служебных скриптов)?
- Заголовок H1?
- Мета-теги?
- Основной текстовый контент?
Проверка ответа сервера: сравните HTTP-заголовки, особенно:
- Код ответа (должен быть 200 для обоих вариантов)
- Заголовок Canonical (самостоятельно или генерируется)
- Проверьте в индексе Google:
site:yourdomain.com inurl:"параметр=" - Проверьте позиции страниц с параметрами и без
- Проанализируйте трафик на параметризованные страницы
Создайте таблицу принятия решений:
| Параметр | Меняет контент? | Важен для пользователей? | Трафик | Решение |
|---|---|---|---|---|
id= | Да | Критично | Высокий | Никогда не блокировать |
sort= | Нет (визуально) | Да | Средний | Clean-param возможно |
session_id= | Нет | Нет | Нет | Clean-param, но не disallow |
РЕАЛЬНЫЕ КЕЙСЫ ИЗ ПРАКТИКИ
Ситуация: разработчик добавил Disallow: /*?* в robots.txt, чтобы "почистить" URL от параметров.
Результат: через месяц из индекса пропали все товары, доступные только через product.php?id=XXX.
Решение: срочное удаление директивы, переиндексация, восстановление трафика заняло 4 месяца.
Ситуация: в clean-param добавлен параметр ?date= для новостей.
Результат: не индексировались страницы архива по датам.
Решение: удаление парамета из clean-param, настройка правильной пагинации.
Ситуация: сайт с активным использованием ?sessionid= в URL, но без какой-либо обработки в robots.txt.
Результат: 90% краулингового бюджета тратилось на обход дублей.
Решение: внедрение cookies для сессий + аккуратная настройка clean-param.
ИНСТРУМЕНТЫ ДЛЯ МОНИТОРИНГА И КОНТРОЛЯ
- Google Search Console → Отчет "Покрытие" → Исключенные → Просканированные, но не проиндексированные
- Яндекс.Вебмастер → Индексирование → Структура сайта → Анализ robots.txt
- Screaming Frog → Анализ параметров через Configuration → Spider
- Лог-файлы сервера — самый точный источник информации о том, как роботы видят ваш сайт
- Google Analytics → Поведение → Содержание сайта → Все страницы (смотреть на параметры)
ЗАКЛЮЧЕНИЕ: ГЛАВНЫЕ ПРИНЦИПЫ БЕЗОПАСНОЙ РАБОТЫ С ПАРАМЕТРАМИ
- Принцип минимального вмешательства: не добавляйте параметры в
clean-paramилиdisallowбез четкого понимания последствий. - Приоритет пользовательского опыта: если параметр важен для пользователей (фильтры, сортировка, пагинация) — он важен и для поисковых систем.
- Тестирование в безопасной среде: все изменения сначала тестируйте на staging-окружении с мониторингом индексации.
- Постепенное внедрение: при работе с крупными сайтами вносите изменения постепенно, по группам параметров.
- Постоянный мониторинг: после любых изменений в robots.txt отслеживайте:
- Количество проиндексированных страниц
- Позиции ключевых запросов
- Органический трафик
- Ошибки сканирования в Search Console
- Документирование: ведите внутреннюю документацию по всем параметрам сайта и правилам их обработки.
Помните: ошибки в управлении GET-параметрами — одни из самых коварных в SEO. Они могут месяцами оставаться незамеченными, постепенно снижая видимость сайта. Будьте осторожны, тестируйте и анализируйте. Ваша задача — не "почистить" URL любой ценой, а обеспечить максимальную видимость полезного контента в поисковых системах.
Глубокий разбор для интернет-магазинов: битва с параметрами за краулинговый бюджет и трафик
Для интернет-магазина GET-параметры — это не просто техническая помеха, а основной канал взаимодействия с пользователем. Их полная блокировка убьет функциональность, а игнорирование — уничтожит SEO. Задача — найти баланс и превратить параметры из врага в инструмент привлечения длинного хвоста запросов.
Оглавление
Категории параметров в e-commerce и стратегия для каждой
| Параметр / Группа | Пример | Цель пользователя | SEO-риск | Рекомендуемая стратегия |
|---|---|---|---|---|
| Фильтры и атрибуты | ?color=red, ?size=42, ?material=cotton, ?brand=nike | Сужение выбора по характеристикам | Массовое дублирование контента. Создание "тонкого" контента (страница с одним товаром после фильтрации). | Селективная индексация. Индексируем только комбинации с высокой частотностью запросов и собственным контентом (наполненная категория, фильтр по бренду). Все остальные — rel="canonical" на родительскую категорию + noindex для "пустых" состояний. |
| Сортировка | ?sort=price_asc, ?order=popularity | Изменение порядка товаров | Дублирование основной категории. Потеря краулингового бюджета. | Единый канонический URL без параметров сортировки. Использовать rel="canonical" на основную страницу. Для UX реализовать сортировку через JavaScript или изменение data- атрибутов без изменения URL, либо через хэш (#sort-price). |
| Пагинация | ?page=2, ?p=3 | Навигация по товарам | Разрыв сигналов (ссылочный вес, поведенческие факторы) между страницами. | Обязательное использование rel="next" и rel="prev". Указание канонической страницы на себя для каждой страницы пагинации (например, page=2 канонична на page=2). Это говорит поисковику, что это — часть серии. |
| Вид отображения | ?view=list, ?view=grid | Изменение интерфейса | Дублирование. | Игнорирование. Использовать rel="canonical" на версию по умолчанию. Идеально — хранить выбор пользователя в cookie/session, не меняя URL. |
| Сессия и отслеживание | ?sessionid=abc123, ?affiliate_id=789, utm_* | Аналитика, партнерские программы | Дублирование, размывание ссылочного веса. | Жесткое исключение. Блокировка в Google Search Console (раздел "Параметры URL"). Использование rel="canonical". Настройка правил перезаписи/редукции URL на стороне сервера для внутренней перелинковки. |
Продвинутая тактика: какие страницы с параметрами СТОИТ оставить в индексе?
Главный вопрос: "Имеет ли страница с параметром уникальную коммерческую ценность и отвечает ли на отдельный кластер поисковых запросов?"
✅ СТОИТ индексировать:
- Фильтр по бренду в общей категории:
/catalog/shoes/?brand=nike. Это полноценная страница с четкой тематикой и высоким спросом. - Фильтр по ключевым характеристикам с высоким спросом:
/catalog/laptops/?ram=16gb. Пользователи ищут именно это. - "Приземленные" фильтры из поиска:
/catalog/sofas/?color=gray&mechanism=book. Страница отвечает на запрос "серый диван-книжка". Ее контент (H1, текст, мета-теги) должен быть уникализирован. - Страницы пагинации для очень больших категорий: Страницы
page=5+могут ранжироваться по низкочастотным запросам и приносить трафик.
❌ НЕ СТОИТ индексировать:
- Пустые или почти пустые результаты фильтрации (1-2 товара). Риск "тонкого контента".
- Множественные пересекающиеся фильтры с малой релевантностью (
?color=blue&size=39&material=leather&heel_height=5cm). Лучше канонизировать на более общую страницу. - Все варианты сортировки.
Техническая реализация для индексируемых страниц с фильтрами:
- Уникальный Title и Description: "Купить кроссовки Nike. Цены от 3 990 руб." вместо "Кроссовки".
- Уникальный текстовый блок: введение, описывающее преимущества выбранного фильтра (например, "Кроссовки Nike для бега сочетают инновационные технологии и стильный дизайн...").
- "Хлебные крошки": они должны отражать путь (Главная > Обувь > Кроссовки > Nike).
- Внутренние ссылки: ссылайтесь на такие страницы с главной, из статей, карты сайта.
Критически важная связка: пагинация + «Показать ещё» + бесконечная прокрутка
Проблема: бесконечная прокрутка без пагинации "ломает" модель краулинга. Поисковый бот не может инициировать действие "прокрутки".
Решение — гибридный подход:
- Реализуйте стандартную HTML-пагинацию (
/catalog?page=2). - Для пользователей используйте JavaScript для подгрузки контента (бесконечная прокрутка или кнопка "Показать ещё").
- Обязательно используйте
rel="next"/"prev"для пагинационных ссылок, даже если они скрыты под кнопкой. - Реализуйте Dynamic Rendering или используйте Hashbang (#!) / PushState для синхронизации URL при скролле, если каждая "порция" товаров должна быть отдельной страницей в индексе (редкий случай).
Чек-лист по настройке для интернет-магазина
- Аудит: выгрузите из логов или GSC все уникальные параметры сайта.
- Ручная разметка: в файле
robots.txtдайте директиваDisallowтолько для служебных параметров (Disallow: /*?sessionid=,Disallow: /*?referrer=). - Google Search Console: в разделе "Параметры URL" отметьте
utm_*,sessionid,aff_idкак "Не влияющие на контент". Дляsort,viewвыберите "Предоставляет другую версию одной и той же страницы". - Канонические теги: на все страницы фильтров и сортировок, которые не хотите индексировать, пропишите
rel="canonical"на базовый URL категории. - Пагинация: проверьте наличие и корректность
rel="next"/"prev". Убедитесь, что у каждой страницы пагинацииselfканоническая ссылка ведет на себя. - Уникальный контент: для стратегически важных страниц фильтров (бренды, топ-запросы) создайте уникальные текстовые описания и мета-теги.
- Sitemap: в карту сайта включайте только канонические версии страниц. Никаких
?sort=или?page=. - Тестирование: запустите краулер (Screaming Frog) в режиме "перебора параметров", чтобы убедиться, что дубли корректно канонизированы, а нужные страницы доступны для индексации.
Итог: в интернет-магазине управление GET-параметрами — это не борьба, а селекция. Вы выступаете в роли строгого редактора, который из миллиона возможных комбинаций URL отбирает десятки тысяч качественных, релевантных поисковым запросам страниц, и четко указывает поисковикам, как обращаться с остальными. Это высший пилотаж технической SEO-оптимизации, напрямую влияющий на краулинговый бюджет и объем органического трафика.
Мониторинг и постобработка: как отслеживать результаты и что делать после внедрения?
После того как вы настроили обработку GET-параметров — установили canonical-ссылки, обновили robots.txt и применили другие технические решения, — работа не заканчивается. Самая большая ошибка — это внедрить изменения и забыть о них. Неправильная настройка может привести к неожиданным последствиям, а корректная — потребует времени для полноценного эффекта.
В этом разделе я расскажу, как правильно мониторить результаты, на что обращать внимание и какие шаги предпринимать в постобработке.
Оглавление
Что и как отслеживать: ключевые метрики
1. Отслеживание индексации (первые 2-8 недель)
| Инструмент | Что проверять | Частота | Ожидаемые изменения |
|---|---|---|---|
| Google Search Console | • Отчет "Покрытие" → "Исключено" (ищите "Дубль без выбранного пользователем канонического") • Отчет "Статус индексации URL" • Поиск по сайту: site:вашдомен.com ?utm_ | 1 раз в неделю | Количество дублей должно уменьшаться. Параметризованные URL из "Исключено" могут временно увеличиться — это нормально, пока Google переиндексирует. |
| Яндекс.Вебмастер | • "Индексирование" → "Страницы в поиске" • Проверка ответа сервера для ключевых URL с параметрами | 1 раз в 2 недели | Яндекс медленнее реагирует на изменения. Эффект от clean-param может появиться через 3-4 недели. |
| Прямые запросы в поиске | • site:домен.com inurl:"?utm_"• site:домен.com inurl:"?sort="• site:домен.com "?gclid=" | 1 раз в месяц | Постепенное исчезновение служебных параметризованных URL из выдачи. |
2. Мониторинг трафика и позиций
// Пример настройки сегмента в Google Analytics // для отслеживания трафика на канонические vs параметризованные URL: Сегмент "Канонические страницы": Условие: "Хост + путь страницы" не содержит "?" (или Регулярное выражение: ^[^?]*$) Сегмент "Страницы с параметрами": Условие: "Хост + путь страницы" содержит "?"
Что смотреть в Google Analytics и Яндекс.Метрике:
- Изменение глубины просмотра — после устранения дублей пользователи должны лучше ориентироваться на сайте.
- Снижение показателя отказов на ключевых страницах — канонические URL получают больше внимания.
- Распределение трафика — доля параметризованных URL должна снижаться, канонических — расти.
В инструментах отслеживания позиций (Ahrefs, Serpstat, KeyCollector):
- Отслеживайте позиции именно по каноническим URL.
- Если раньше позиции "плавали" между разными версиями страницы, после настройки они должны стабилизироваться.
3. Краулинговый бюджет и здоровье сайта
| Метрика | Инструмент для проверки | Что означает улучшение |
|---|---|---|
| Количество проиндексированных страниц | GSC → "Покрытие" → "Действительные" | Число должно стать ближе к реальному количеству уникальных страниц (без дублей) |
| Ошибки сканирования | GSC → "Статистика обхода" | Уменьшение ошибок 404 для параметризованных URL, которые вы заблокировали |
| Время сканирования | Логи сервера, GSC → "Статистика обхода" | Робот тратит меньше времени на дубли, больше — на уникальный контент |
| Страницы, исключенные роботом | GSC → "Покрытие" → "Исключено" | Появление страниц с пометкой "Дубликат" — это нормально, это означает, что Google правильно определил каноническую версию |
Критические точки контроля: когда бить тревогу
Ситуация 1: пропали из индекса важные страницы
Симптомы:
- В GSC в отчете "Покрытие" резко выросло количество "Исключено" → "Просканировано, но не проиндексировано"
- Ключевые страницы (товары, статьи) перестали находиться по запросу
site:домен.com/ключевая-страница
Возможные причины:
- Слишком агрессивные правила в robots.txt:
Disallow: /*?*заблокировал ВСЕ страницы с параметрами, включаяproduct.php?id=123. - Ошибка в канонических ссылках: на всех страницах с параметрами стоит canonical на главную страницу, а не на их основную версию.
- Конфликт директив: на одной странице одновременно canonical и noindex, или noindex вместе с разрешением в robots.txt.
Срочные действия:
# 1. Проверьте текущий robots.txt, откатите опасные правила: # ВМЕСТО ЭТОГО (опасно!): Disallow: /*?* # ИСПОЛЬЗУЙТЕ (точечно): Disallow: /*?utm_ Disallow: /*?gclid= Disallow: /*?sessionid= # 2. Проверьте канонические ссылки на ключевых страницах: # Правильно для товара с ID: <link rel="canonical" href="https://site.com/product/123" /> # НЕПРАВИЛЬНО: <link rel="canonical" href="https://site.com/" />
Ситуация 2: дубли не исчезают через 2 месяца
Симптомы: в GSC по-прежнему много "Дублей", параметризованные URL все еще в индексе.
Причины и решения:
| Причина | Решение | Срок исправления |
|---|---|---|
| Google не видит canonical | Проверьте, что тег находится в <head>, а URL абсолютный и корректный. Используйте инструмент "Проверка URL" в GSC. | 1-3 недели после исправления |
| Динамическое создание параметров | Параметры генерируются JavaScript'ом после загрузки страницы. Нужно внедрять canonical на серверной стороне. | 2-4 недели |
| Внутренние ссылки ведут на дубли | Проведите аудит внутренней перелинковки, замените ссылки с параметрами на канонические URL. | 3-6 недель |
| Внешние ссылки ведут на дубли | Используйте 301 редирект с популярных параметризованных URL на канонические. | 4-8 недель |
Ситуация 3: упал трафик на разделы с фильтрами
Симптомы: после настройки clean-param для параметров фильтрации (?color=, ?size=) упал трафик из поиска на эти страницы.
Ошибка: вы "слишком хорошо" поработали и скрыли от индексации страницы, которые должны были в ней остаться.
Решение:
- Пересмотрите классификацию параметров. Фильтры, которые создают уникальные подборки товаров (например,
?category=premium-shoes), должны быть индексируемыми. - Для индексируемых фильтров:
- Установите canonical на самих себя
- Добавьте уникальные title и description
- Создайте уникальный текстовый контент на странице фильтра
Пошаговый план постобработки (первые 90 дней)
Первые 7 дней: активный мониторинг
- Ежедневно: проверяйте отчеты GSC на предмет резких изменений в "Покрытии".
- Через 3 дня: проведите точечный краулинг Screaming Frog для проверки корректности canonical.
- Через 7 дней: сделайте первый запрос в Google
site:домен.com inurl:"?параметр="для ключевых параметров.
30 дней: первый анализ результатов
Чек-лист через 30 дней:
- Количество "Дублей" в GSC уменьшилось на ___%
- Количество индексированных страниц стабилизировалось
- В поиске не находятся ключевые служебные параметры (utm_, gclid)
- Трафик на канонические URL вырос, на параметризованные — упал
- Нет ошибок сканирования для заблокированных параметров
- Яндекс.Вебмастер показывает корректную обработку clean-param
60-90 дней: финальная оценка и оптимизация
- Полный аудит: запустите полный краулинг сайта с анализом всех оставшихся параметров.
- Анализ логов: изучите логи сервера — какие параметры все еще активно сканируются роботами.
- Оптимизация правил: уточните robots.txt на основе данных логов.
- Документирование: зафиксируйте все примененные правила и их эффект.
Кейс: реальные сроки и результаты
Проект: Интернет-магазин, 10 000 товаров, активно использовались UTM-метки и параметры фильтрации.
| Действие | Срок внедрения | Заметный эффект | Полный эффект |
|---|---|---|---|
| Установка canonical для UTM | 1 день | Через 2 недели | Через 6 недель |
| Настройка clean-param в robots.txt | 1 день | Через 4 недели (Яндекс) | Через 8 недель |
| Оптимизация пагинации (prev/next) | 3 дней | Через 3 недели | Через 10 недель |
| Исправление внутренних ссылок | 7 дней | Через 2 недели | Через 5 недель |
Итоговые результаты через 3 месяца:
- Краулинговый бюджет: +35% (робот стал находить на 30% больше новых страниц)
- Индексация: количество проиндексированных страниц уменьшилось с 85K до 52K (убрали дубли)
- Трафик: +18% органического трафика (концентрация на канонических URL)
- Позиции: стабилизация позиций по коммерческим запросам
Инструменты для постоянного мониторинга
Бесплатные:
- Google Search Console — основной инструмент
- Яндекс.Вебмастер — для отслеживания clean-param
- Google Analytics — сегменты по URL
- Log File Analyzers (Screaming Frog, ELT) — анализ логов сервера
Платные (но эффективные):
- Screaming Frog — регулярные аудиты с сохранением конфигураций
- Botify, OnCrawl, DeepCrawl — для крупных сайтов
- Ahrefs, Semrush — мониторинг позиций и обратных ссылок на разные версии URL
Чек-лист постобработки (распечатайте и отмечайте)
Еженедельно (первые 4 недели)
- Проверить GSC → "Покрытие" на новые ошибки
- Убедиться, что ключевые страницы в индексе
- Проверить 2-3 параметризованных URL через "Проверку URL" в GSC
Ежемесячно (после 1-го месяца)
- Сборка запросов
site:домен.com inurl:"?параметр="для основных параметров - Анализ логов сервера за последний месяц
- Обновление документации по параметрам
Квартально
- Полный краулинг сайта с анализом параметров
- Аудит всех canonical-ссылок
- Корректировка robots.txt на основе данных логов
- Анализ динамики трафика и позиций
Золотые правила постобработки
- Не паникуйте из-за временного роста "Исключенных" страниц в GSC — это нормальный процесс переиндексации.
- Яндекс реагирует медленнее Google — дайте 4-8 недель на clean-param.
- Всегда проверяйте robots.txt через валидаторы GSC и Яндекс.Вебмастера.
- Документируйте ВСЕ изменения — когда, какие параметры, какое решение. Это спасет при аудите через полгода.
- Сравнивайте логи сервера до и после — это самый объективный показатель эффективности.
Заключение по мониторингу
Управление GET-параметрами — это не разовая акция, а циклический процесс: Аудит → Внедрение → Мониторинг → Корректировка.
Самая частая ошибка SEO-специалистов — прекращать мониторинг через 2 недели после внедрения. Полный цикл переиндексации занимает 60-90 дней. Именно через этот период можно объективно оценить результаты.
Помните: ваша цель — не механически "почистить" URL, а направить максимум краулингового бюджета и ссылочного веса на стратегически важные страницы. Качественный мониторинг помогает не только зафиксировать успех, но и вовремя обнаружить ошибки, которые могут стоить вам трафика и позиций.
Начните с малого: выделите 30 минут в неделю на проверку ключевых метрик. Эта привычка окупится сторицей, когда вы вовремя заметите проблему или зафиксируете рост показателей благодаря вашей работе.